How to Train a Generative AI Model?
Training a generative AI model involves defining objectives, collecting high-quality data, selecting the right architecture, and optimizing performance. Let's understand cost factors like computational power and cloud services, and explore strategies to reduce expenses.

Do you want a generative AI model but remain unsure about the best approach? As AI transforms industries from content creation to software development, custom model production stands as an increasingly valuable capability. This process demands a method that covers the selection of an appropriate model architecture, the acquisition of high-quality data, and parameter optimization. In this guide, we describe the entire process that leads to a generative AI model. The steps involve data collection, model selection, training methods, and evaluation metrics.
What is a Generative AI Model?
Generative AI models are designed to create new content—whether text, images, music, or code—by learning from vast datasets. Unlike traditional AI systems that classify or predict based on existing data, generative AI models generate entirely new outputs that mimic human creativity and reasoning. You can partner with a generative AI development company that addresses every stage of the process. They train AI models with high-quality data, optimize performance, refine outputs, and deploy final solutions for real-world applications. Generative AI is revolutionizing industries by automating content creation and improving productivity. Consider these statistics:
- 90% of online content could be AI-generated by 2026, according to recent studies.
- 83% of businesses already use AI-powered tools for content automation, with 35% using generative AI for marketing, per McKinsey & Co.
- OpenAI’s ChatGPT reached 100 million users within two months of launch, making it the fastest-growing consumer application in history.
Generative AI models are shaping the future of automation and creativity. Businesses that train AI models can scale operations, improve customer experiences, and unlock new revenue streams. However, successful implementation requires high-quality data, great computing power, and model optimization strategies.
The Role of enerative AI Training Data
Training data plays a fundamental role in the development of generative AI models. These models do not inherently "know" how to generate content; instead, they learn patterns, relationships, and structures from the data they are trained on. The quality, diversity, and quantity of the dataset directly impact the model’s ability to generate accurate, coherent, and creative outputs. Here are the key criteria for generative AI training data:
- AI models trained on a wide range of data perform better across different inputs. For text models, this means incorporating multiple writing styles, languages, and subject areas. For image models, diversity in composition, lighting, and textures provides better generalization. Without sufficient variety, the model may develop limited perspectives. For instance, an AI trained only on Western art styles would struggle to generate traditional Asian artwork.
- Larger datasets help AI models identify deeper patterns and produce more accurate outputs. Models like GPT-4 reportedly trained on trillions of words, while LAION-5B, a dataset for image models, contains billions of samples. However, diminishing returns apply when additional data does not introduce new learning opportunities. Quality matters more than sheer size, as excessive low-value data can slow training.
- The dataset must align with the model’s intended use case. A chatbot designed for customer support should not be trained on informal social media conversations, just as an AI medical assistant should rely on peer-reviewed healthcare literature rather than general internet articles. Training on domain-specific data improves accuracy, provides reliability, and minimizes irrelevant or misleading output.
- Poor-quality data reduces model reliability and leads to inaccurate outputs. Cleaning the dataset involves removing duplicates, fixing mislabeled content, and filtering biased or low-resolution samples. For example, a facial recognition AI trained on low-quality images may fail to distinguish subtle facial details.
The scope and quality of the training data directly impact the AI's ability to generalize, meaning a well-trained model can produce high-quality outputs across diverse prompts while a poorly trained one may generate biased, repetitive, or nonsensical results.
How to Train a Generative AI Model?
Generative AI models present opportunities to produce creative content and tackle complex tasks in many fields. Their creation, though intricate, involves a structured sequence of steps that lead to success in text generation, image production, or other imaginative pursuits. Below is an overview of the journey and the important decisions that lead to high-quality outcomes. Here is how you train AI models.
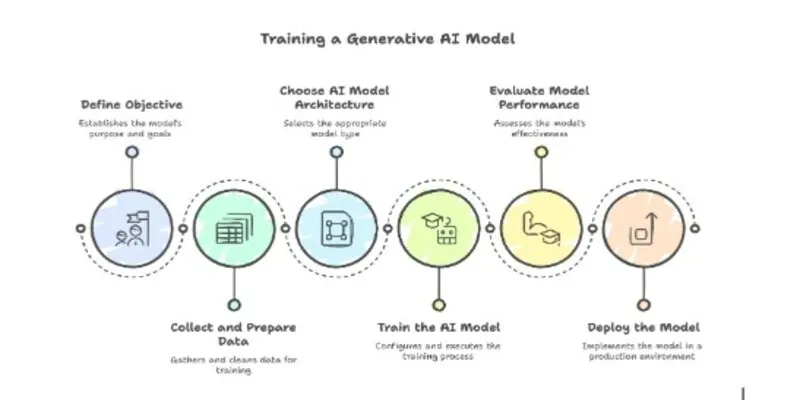
Step 1. Define the objective
A clear objective forms the foundation of a successful project. This stage addresses the business or research goal that the generative AI model must accomplish. The focus may involve text generation, image synthesis, music composition, or another creative domain. Clarity regarding the model’s purpose aids in choosing an appropriate dataset, measuring success, and establishing a timeline. A thorough plan at this stage simplifies later phases and prevents scope creep.
Step 2. Collect and prepare data
High-quality data fuels the learning process. At this stage, teams gather a large and representative dataset that matches the chosen domain. A balanced dataset is important for an accurate model. When the data arrives from various sources, the next phase involves the removal of duplicates, the conversion of file formats, and the assignment of labels or categories (if necessary). Any data that contains errors, inconsistencies, or biases undergoes correction or elimination. A dataset that reflects the model’s intended use case increases the reliability and fairness of the final results.
The type of training data depends on the chosen AI model:
- For text-based models, large-scale datasets such as Wikipedia articles, scientific papers, or conversational dialogues are necessary.
- For image generation models, datasets like ImageNet, COCO, or custom high-resolution images are needed.
- For audio models, diverse speech recordings, music tracks, and environmental sounds are important.
When sourcing data, you need to think about legal compliance with intellectual property laws. Many AI models rely on publicly available datasets, but businesses may need to obtain licensing agreements for proprietary data.
Step 3. Choose the right AI model architecture
The choice of model architecture dictates the model’s capabilities and usability. Neural networks designed for generative tasks include options such as Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), Transformer-based models (e.g., GPT variants), and diffusion models. The selection process considers data type, hardware constraints, and project goals. For instance, text-focused use cases often benefit from Transformers, while image-oriented solutions may rely on GANs or diffusion-based approaches. This step also accounts for the complexity of hyperparameters and the computational resources needed for training.
Step 4. Train the AI model
The configuration of a training environment is important at this stage. The team specifies batch size, learning rate, and optimizer choice, along with the duration of training in terms of epochs or steps. Frameworks such as TensorFlow or PyTorch simplify the iterative process of forward and backward passes. During each pass, the model processes data, calculates loss, and updates weights to reduce errors. Techniques such as early stopping and parameter regularization minimize excessive fit to the training data. The team observes validation metrics, checks for convergence, and makes adjustments to hyperparameters when results fall short of expectations.
While generative AI models have shown impressive capabilities, data limitations and model scalability remain major hurdles. AI advancements have slowed due to a bottleneck in high-quality training data availability, forcing companies to find innovative ways to improve model performance
Step 5. Evaluate model performance
Once the model reaches a stable state, the team measures its performance with quantitative and qualitative methods. Standard metrics vary according to the domain. For text generation, BLEU or ROUGE scores may apply. For images, Fréchet Inception Distance (FID) or Inception Score (IS) may be relevant. Qualitative analysis often reveals subtle flaws that remain hidden in numerical evaluations. Stakeholder feedback or a review by domain experts provides alignment with business objectives. If results are below target levels, the dataset or model architecture may undergo revisions, or additional data may be incorporated.
Step 6. Deploy the model
Deployment in a production environment concludes the development cycle. The team bundles model weights and code into a format that suits the chosen infrastructure. Some organizations prefer container-based solutions (e.g., Docker), while others rely on cloud services with preconfigured runtime environments. The creation of an inference endpoint enables real-time or batch predictions. Ongoing oversight is necessary: performance metrics, latency, and resource utilization may fluctuate as user demands increase. Prompt updates or retraining sessions address drift in data distribution or newly discovered shortcomings. This step helps the model to deliver real-world value and remains useful over time.
This six-step approach—covering the definition of objectives, data gathering, architecture selection, training procedures, performance assessments, and deployment—creates a roadmap for the development of a generative AI model. A project that follows these practices stands a higher chance of success, delivers meaningful outputs, and adapts to evolving requirements.
Cost Considerations in Generative AI Training
Training a generative AI model requires substantial computational resources, high-quality training data, and ongoing maintenance. The cost of training generative AI models depends on several factors, including model complexity, dataset size, hardware requirements, and cloud service expenses. Several key elements influence the overall cost of generative AI training data processing and model development:
| Factor | Impact of Cost | Example Costs | ||
|---|---|---|---|---|
| Model complexity | Larger and more sophisticated models require more GPUs, storage, and training time. | GPT-3 training cost $4.6 million (OpenAI) | ||
| Dataset size & quality | High-quality, diverse datasets increase costs due to licensing, storage, and processing requirements. | Datasets $10,000–$100,000+ | ||
| Computational power | Training requires specialized hardware (GPUs, TPUs) or cloud computing services. | NVIDIA A100 GPU instance: $32/hour (AWS) | ||
| Cloud vs. on-premise | Cloud solutions scale easily but incur ongoing costs; on-premise setups require high initial investment. | Cloud TPU training $10,000+/month | ||
| Training duration | Longer training cycles increase computing costs, especially for large datasets and complex models. | Fine-tuning BERT $7,000+ per run | ||
| Energy consumption | Power-intensive computations impact costs, particularly for large-scale models. | AI training energy use 700,000 kWh per model | ||
| Ongoing maintenance | Continuous fine-tuning, retraining, and updates require additional computing resources and expert oversight. | Retraining cost Up to 20% of initial training |
Here are some strategies to manage costs:
- Instead of training a generative AI model from scratch, fine-tuning existing models reduces expenses.
- Services like AWS SageMaker, Google Cloud AI, and Microsoft Azure AI offer infrastructure for training AI models.
- Techniques such as quantization or pruning reduce computational requirements and limit hardware costs.
- The division of workloads across multiple machines accelerates the training phase and decreases total compute time.
- Execution at off-peak hours and the use of power-efficient hardware minimize power costs.
The cost to build generative AI models varies based on scale and complexity. Organizations must decide whether to develop a model from scratch or refine an existing model, balancing budget and objectives. When teams use cloud-based AI solutions, apply optimization techniques, and manage resources, they create cost-saving generative AI processes and maintain high-quality model performance.
Conclusion
Building a generative AI model is a complex yet rewarding process that demands careful planning and execution. Each step—from the definition of the objective to the final deployment of the model—plays a key role in generating high-quality, relevant, and scalable outputs. Without a clear objective, models may lose focus and fail to deliver meaningful results. Now, you know how to train a generative AI model. As AI continues to evolve, the ability to train generative AI models will remain an important skill for businesses and developers seeking to improve automation and customer experiences and drive innovation.
FAQ
How long does it take to train a generative AI model?
The training duration depends on factors like model complexity, dataset size, and computational resources. Small models with limited datasets may finish in a few hours or days, while large-scale models—like GPT-4 or Stable Diffusion—can take weeks or even months on high-performance GPUs or TPUs. Fine-tuning an existing model is much faster, often wrapping up in several hours or a few days, depending on the dataset and architect.
Can I train a generative AI model without high-end GPUs or cloud computing?
Training a generative AI model from scratch without specialized hardware is difficult but not impossible. Smaller models can be trained using local machines with high-end consumer GPUs (e.g., NVIDIA RTX 4090), but large models require dedicated cloud services like AWS, Google Cloud TPUs, or Azure AI for feasible training times. Alternatives include using pre-trained models and applying techniques like fine-tuning or LoRA (Low-Rank Adaptation) to reduce hardware requirements.
How often should a generative AI model be retrained?
The frequency of retraining depends on the type of data and application. AI models that rely on rapidly evolving information, such as news summarization or product recommendations, require frequent retraining (weekly or monthly). Models with more stable datasets, like image generators, can be updated every few months to a year.


