Multimodal AI: Creating Artificial Super Senses
Multimodal AI is a leap towards building more human-like AI. Unlike traditional AI, which requires a single type of data, it incorporates diversified data sources, such as text, image, audio, and video, to gain deeper insights and offer sophisticated, accurate, and reliable solutions.

What is Multimodal AI?
Multimodal AI, also Multimodal Artificial Intelligence, is a recently developed branch of AI that concentrates on processing multiple sources of information called modalities. With a broader range of information (through modalities), AI can better understand the observable environment. These modalities include, but are not limited to:
- Text: Documents, blog posts, emails, and social media posts.
- Images: Photos and medical scans.
- Audio: Speech and music.
- Sensor data: From devices such as cameras, LiDAR, and accelerometers.
- Genomics data: DNA sequences, transcriptomic data, or protein sequences.
- Chemical data: This includes information about molecules, their structures, properties, and reactions. Examples include chemical formulas, spectra, and mass spectrometry data.
- Geospatial data: This refers to data with a geographic location component. Examples include GPS coordinates, satellite imagery, and weather data.
- Network data: This represents connections or relationships between entities. Examples include social networks, citation networks, and transportation networks.
- Time series data: This data captures measurements taken regularly over time. Examples include stock prices, sensor readings, and patient vital signs.
- Haptic data: This data captures touch sensations. Examples include data from VR controllers or wearables that track hand movements.
- Textual metadata: This refers to data that describes other data, often in the form of tags, labels, or annotations. Examples include image captions, document titles, and authorship information.
Unlike traditional AI models that are limited to processing single data types, such as text or images, multimodal AI has the unique ability to simultaneously process and interpret multiple sensory modes. This mirrors human sensory processing, where our senses of sight, sound, and touch work together to provide a comprehensive understanding of our environment. This human-like capability of multimodal AI instills confidence in its reliability and potential in healthcare.
Imagine a doctor trying to diagnose a complicated neurological condition. Usually, doctors look into medical scans like MRIs, review patient medical history, and perform physical examinations. However, on the other hand, a multimodal AI system employs additional data sources to provide a more comprehensive picture:
- Brain scans (MRI/EEG): To identify abnormalities in brain structure or activity.
- Genetic data: To check for known genetic markers linked to neurological conditions.
- Wearable sensor data: To measure activity changes that might indicate the condition, such as tremors or sleep patterns.
- Speech analysis: To help recognize the slightest changes in the manner of speaking that might be a sign of neurological disease.
By analyzing all this data together, the multimodal AI system for disease diagnosis could assist the doctor in:
- Developing near-to-accurate diagnoses where human capabilities could miss minute details.
- estimating disease progression and consider individualized treatment options.
- Creating personalized rehab protocols for each patient depending on their symptoms, risk factors, and acceptance.
Why is Multimodal AI Important?
The human brain is naturally designed for multimodal processing. We constantly receive data from our environment through the five senses i.e. sight, sound, touch, smell, and taste. By analyzing the data from each sensory node (modality) and merging it to attain understandable information, we make decisions. Multimodal AI is a type of AI that replicates this human capacity by fusing data from various inputs or channels. This approach offers several advantages over traditional AI:
- Richer understanding: Multimodal AI can gain insight into a situation by analyzing several data sources.
- Improved accuracy: Using information from multiple sources is more beneficial in predicting and classifying certain items than relying on information from a single source.
- Enhanced decision-making: Multimodal AI can empower various applications to make more informed decisions by considering a broader range of factors.

Are Multimodal AI and Compound AI Systems the same?
In a nutshell, No!
Both multimodal AI and compound AI systems deal with complexity by combining different elements, but they do so in distinct ways:
Multimodal AI focuses on processing and integrating data from various sources (modalities), such as text, images, audio, sensor data, and genomics. Considering information from different angles aims to create a more comprehensive understanding of a situation.
Compound AI systems, on the other hand, integrate multiple AI models that work together to achieve a specific goal. These models can be of different types, like a combination of a rule-based system and a machine-learning model.
Here's a table summarizing the key differences:
| Feature | Multimodal AI | Compound AI System |
|---|---|---|
| Focuses on | Integrating data from various modalities | Integrating multiple AI models |
| Data Types | Text, images, audio, sensor data, etc. | Outputs from various AI models |
| Goal | Gain a richer understanding by combining information | Achieve a complex goal by combining the strengths of different AI models |
| Example | Combining image recognition and text analysis for medical diagnosis | A recommendation system that combines collaborative filtering and content-based filtering |
Still didn’t get that? Here's an analogy to illustrate the difference:
Imagine a detective solving a case:
- A multimodal AI is like a detective gathering evidence from various sources like fingerprints (images), witness testimonies (text), and DNA samples (genomics data). By combining this information, they get a clearer picture of the crime.
- A compound AI system is like a detective collaborating with a team of specialists. There might be a handwriting expert analyzing the witness testimonies, a forensics expert examining the fingerprints, and a DNA analyst interpreting the samples. Each specialist brings their expertise to the table, and the detective combines their findings to reach final conclusion.
Core Concepts and Techniques in Multimodal AI
Multimodal AI combines various approaches using technological tools to perform effective data analysis from multiple inputs. Here, we'll explore some of the fundamental concepts that drive this technology:
Data Fusion
The idea behind multimodal AI is data fusion, which involves merging data from multiple sources. This fusion can occur at various levels:
Feature-level Fusion
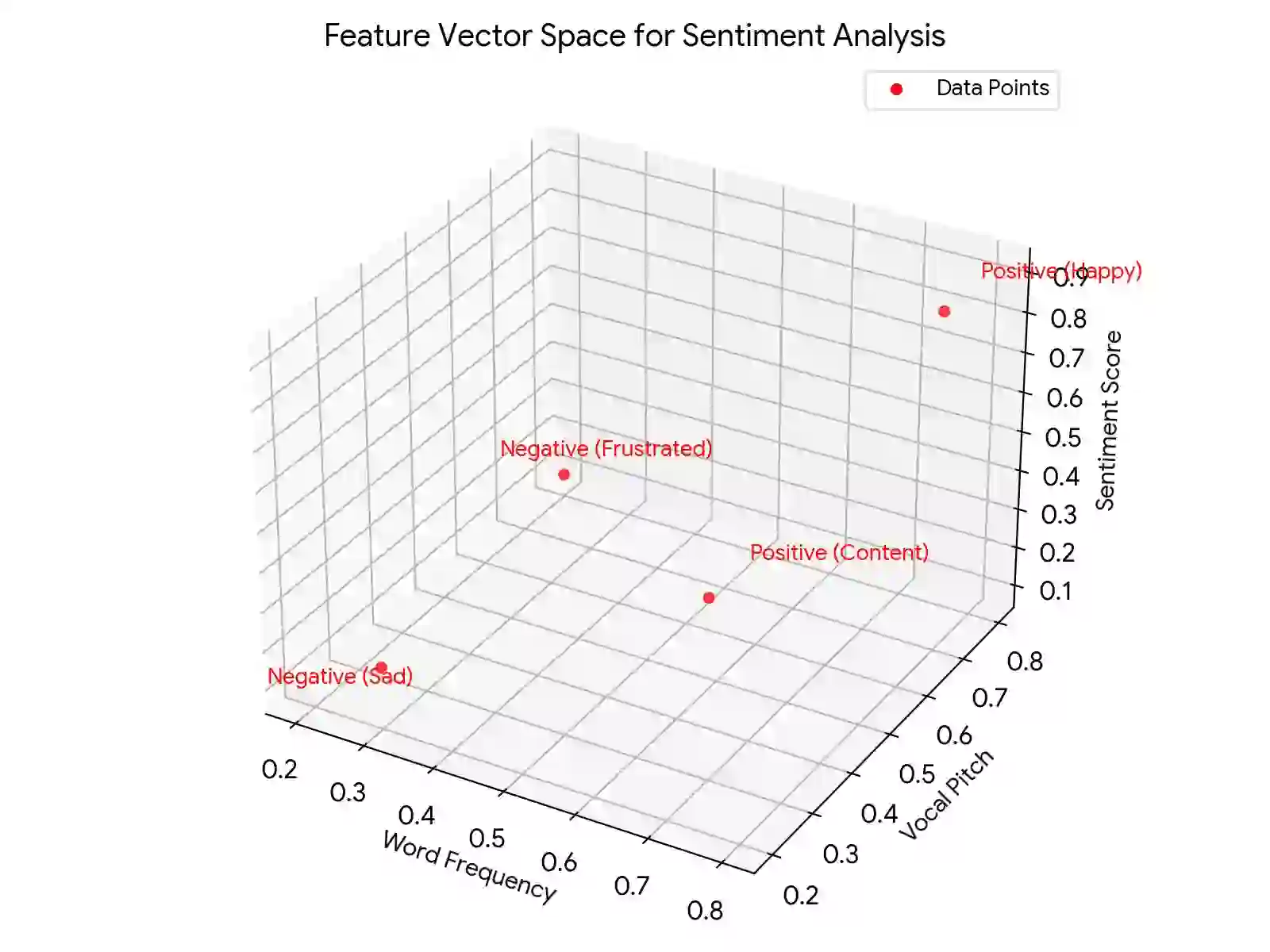
Here, features extracted from individual modalities are combined into a single feature vector. For instance, in sentiment analysis that combines text and audio data, features like word frequencies from text and vocal intonations from audio are fused into a single vector for sentiment classification.
How Feature-Level Fusion works?
Fusing word frequencies and vocal intonations for sentiment analysis in multimodal AI involves creating a feature vector that combines information from both sources. Here's a breakdown of the process:
1. Feature Extraction
- Text: Words in the text are analyzed to calculate their frequencies. This creates a set of values representing how often each word appears.
- Audio: Vocal intonations are analyzed to extract features like pitch (how high or low the voice is) and loudness. These features capture the emotional tone of the speaker.
2. Vector Creation
- Both sets of features (word frequencies and intonation features) are combined into a single vector. This vector acts like a high-dimensional address where each dimension represents a specific feature.
- The size of the vector depends on the number of features extracted from each modality (text and audio).
Here's an analogy: suppose it was a 2-dimensional space instead of many dimensions, with point X showing word frequency and point Y – showing pitch. Words that often carry a positive emotional tone and are spoken with high intonation may be placed high and to the right of this space. An expression of negativity with positive word choice but low inflection would be plotted near the bottom of the Y-axis but higher on the X-axis. This scenario explains why the features blended together to form another “location” for the sentiment in the vector space.
The specific method of combining these features can vary depending on the chosen algorithm. Some common techniques include:
- Concatenation: It involves placing the word frequency features and intonation features next to each other in the vector.
- Weighted Sum: Assigning weights to different features based on their importance for sentiment analysis. (To get the idea of weightage, imagine a courtroom where a witness testifies in high notes and a steno typist records their statements. How will the decision be made? Based on the pitch of a voice or typed document? Obviously, a typed document has more weightage in court.)
By fusing word frequencies and vocal intonations into a single feature vector, the AI can gain a richer understanding of the sentiment expressed. This leads to more accurate sentiment classification than relying on text or audio alone.
Decision-level Fusion
Decision-level fusion is one of the most powerful techniques in artificial intelligence that focuses on improving decisions by using multiple data resources. In contrast with other approaches that rely on using a single dataset for the analysis, this method enables multiple models to work independently with data of different types or modalities. True power comes when these models’ insights are typically aggregated via voting or averaging. Such an approach allows for understanding the issue at stake more comprehensively and making more informed, accurate decisions regarding AI applications in any field.
How can Decision-Level Fusion help you select a perfect movie?
Selecting a movie is not always easy since consumers have many choices. Decision-level fusion, one of the advanced methods used in AI, enables us to reach the best recommendation by considering all crucial pieces of information, as every detective tries to combine the testimonies of multiple witnesses.
Imagine you're planning a movie night. Here's how decision-level fusion can leverage different modalities (types of information) to suggest the ideal film:
- Review Analysis (Text): Evaluate written reviews to discover the critics' and other moviegoers' perceptions. AI models can extract sentiment from the movie, identify the genre of the movie, and get an overall clue regarding the atmosphere of the specified movie.
- Watch History (Clickstream Data): Your prior television watch patterns still have a lot to offer! Based on your watch's view history, the AI can suggest more movies of similar taste.
- Movie Trailer Analysis (Audio/Video): Trailers are, in fact, more like short or brief impressions of movies. The visuals, the music, and even short clips of dialogue can be explained by using AI to discern the different genres, themes, and the general mood of a movie.
- Social Media Buzz (Text): Let the public speak! By analyzing social media posts and comments, one can track people’s expectations and moods regarding new films. Such data can help determine movies that created buzz or received critical reviews.
- Calendar Integration (Time-based Data): A busy week calls for a shorter film! Integrating your calendar, the AI can prioritize movies that fit your schedule, recommending shorter documentaries or comedies if you have a packed week ahead.
- Audio Description Tracks (Text): For blind or partially sighted viewers, audio description presents the path to the movie’s universe. By analyzing these tracks, we can review the fundamental elements of the plot, themes, and tone and make diverse suggestions.
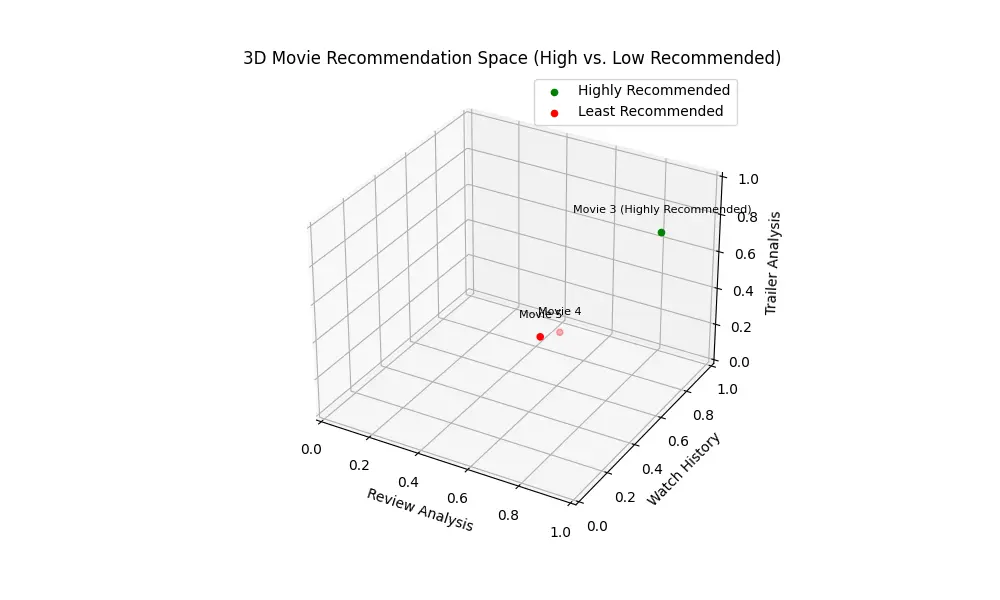
Combining Clues in 3D Space
Imagine a 3D space where each axis represents a modality (e.g., X-axis: Review Analysis, Y-axis: Watch History, Z-axis: Trailer Analysis). Each movie recommendation can be visualized as a point within this space, present at a distance based on its compatibility with each data source.
Making the Final Call: Voting or Averaging
Now comes the decision-making process. Here's how AI combines insights from all modalities:
- Voting: Each modality "casts a vote" for a movie. Movies with the most votes (positive recommendations from most modalities) receive a stronger recommendation.
- Averaging: The AI assigns a score to each movie based on its compatibility with each modality (e.g., how well the reviews align with your taste, how similar the trailer is to movies you enjoyed, OR how much you rely on certain modalities). Before this phase, you can set the weightage/score for each modality. Usually, people give more weight to IMDB rankings and social media buzz. These scores are then averaged to create a final recommendation score.
Through decision-level fusion and various input forms, AI can better understand your preferences and the movie. This results in customized recommendations not limited to genre or popularity hit, making every movie night worthwhile.
Model-Level Fusion: Combining Predictions, Not Features
Model-level Fusion is a technique used in multimodal machine learning where individual models trained on different types of data or "modalities" are combined at the model output stage. This fusion approach involves integrating the outputs from several models, each designed to process a specific type of input, such as text, images, or audio. The integration typically happens through methods like averaging, weighted averaging, voting, or more complex algorithms like Decision trees or Attention Mechanisms that consider how the outputs from different models can best complement each other to make a final decision or prediction.
How Model-level Fusion Works?
1. Individual Model Training: It starts with training individual models where each model trains on a specific data mode. One of the best options for data in the form of images is the Convolution Neural Network (CNN), which effectively identifies patterns and extracts features from pixel configurations. There is no better option for text data than a Recurrent Neural Network (RNN), which can capture sequential dependencies in the data. Likewise, Recurrent Neural Networks (RNN), in general, and Long Short-Term Memory (LSTM) in particular, can handle audio data because they learn temporal relations between notes over time. It is important to note that WaveNet can serve as a feature extractor but not as a model for obtaining audio.
2. Output Generation: Once trained, each model processes its assigned input data independently. This processing generates outputs that can take various forms depending on the task. In image recognition, the output might be class probabilities indicating the likelihood of an object being present (e.g., 80% probability of being a cat). For text analysis, an RNN might output sentiment scores (positive, negative, or neutral) or a summarized representation of the text's content. For audio analysis, Mel-Frequency Cepstral Coefficients (MFCCs) may be used to detect the pitch of voice for sentiment analysis.
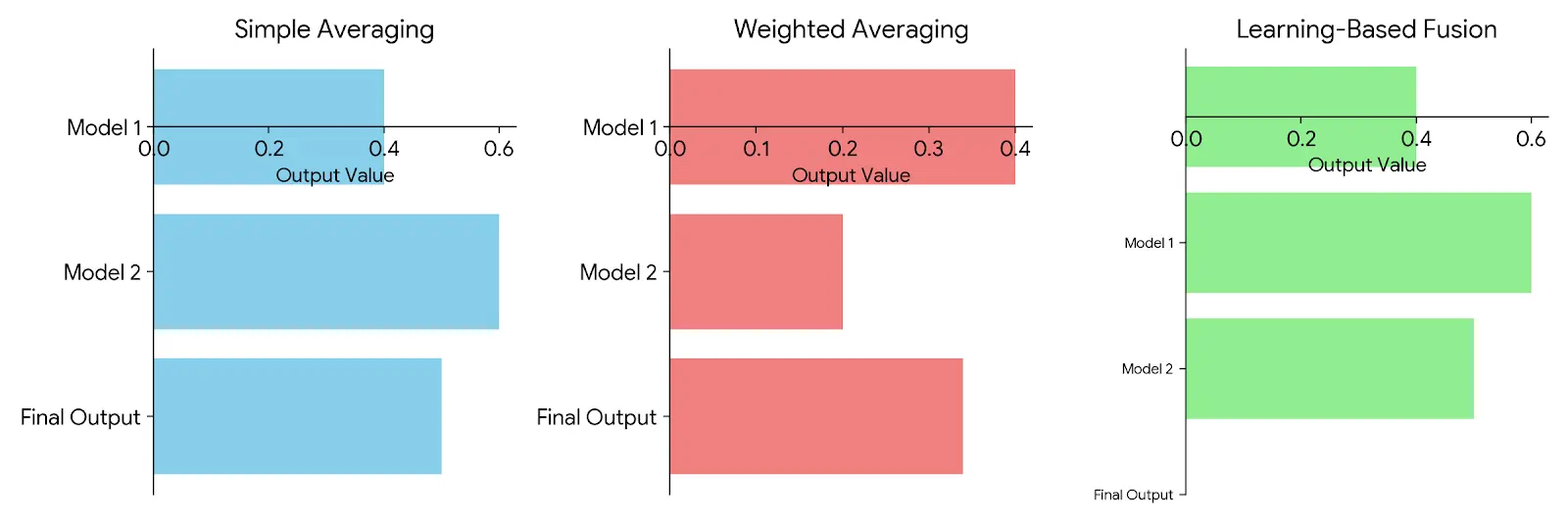
3. Output Integration: Here's where the magic happens! The individual outputs are brought together and fused into a unified representation. This fusion can happen in a few ways:
- Simple Averaging: A straightforward approach averages the outputs from each model. This works well when the models contribute “equally” to the final task.
- Weighted Averaging: However, since some models may be assumed to be more accurate or provide more useful information than others, the contribution of these models in the fusion process can be weighted higher. Weights can be assigned using strategies based on performance metrics such as validation accuracy or the confidence score of the model.
- Learning-Based Fusion: A separate fusion model can be trained in more complex scenarios. This model takes the individual outputs as input and optimizes how to combine them for the specific task. This allows the fusion to be more adaptive and data-driven.
By effectively combining the strengths of various models, model-level fusion empowers AI systems to achieve superior performance in tasks that require understanding multiple modalities. Imagine a self-driving car that fuses camera images (analyzed by a CNN) with radar data (interpreted by another specialized model) to create a comprehensive understanding of its surroundings. This combined view allows for safer and more accurate navigation.
Examples and Analogies
1. Medical Diagnosis: Consider a system intended to identify diseases from different patient health-related information. There is one model that operates with MRI images, the second one processes the written medical history, and the third one deals with blood tests. At the model level, fusion would be accomplished by fusing the diagnosis suggestions obtained from each model to arrive at an average/integrated diagnosis. For instance, if two out of three models point to the probability that a particular condition exists, the system may be inclined to that conclusion, especially knowing that the two models have very high accuracy rates on the signs they consider.
2. Self-driving Cars: In autonomous vehicle technology, different systems process different types of data: cameras capture video, radar systems monitor distances, and audio systems might listen for sirens or other important sounds. Model-level fusion would involve taking the output from these systems, such as obstacle distance, motion vectors from video, and emergency vehicle detection from audio, and integrating them to make driving decisions. The fusion might prioritize certain data under specific circumstances, like giving more weight to the audio detection of sirens in noisy visual environments.
3. Sentiment Analysis: Consider a system tasked with determining the sentiment of a video blog post. Separate models analyze the spoken words, the tone of voice, and the visual expressions of the speaker. Model-level fusion combines these analyses to decide if the overall sentiment is positive, negative, or neutral. For instance, the text might seem positive, but if the tone and facial expressions indicate sadness, the system might conclude the sentiment is negative.
If the tone is high, the face is sad, and the words are negative, but the audience is laughing, how will your AI decide what kind of sentiment is there?
Analogies to Understand Model-Level Fusion
- Cooking: Think of each model as a chef specializing in one dish ingredient, such as meat, vegetables, or sauce. Model-level fusion is like combining efforts to create a well-balanced dish that considers each ingredient's strengths, much like a head chef might adjust the final dish by balancing flavors that come from each specialist.
- Orchestra: Each model is like an instrument section in an orchestra, strings, woodwinds, brass, and percussion. Model-level fusion is the conductor’s role, integrating these sections to produce harmonious music where no single instrument overshadows the others, but all contribute to the overall performance.
Model-level fusion is valuable because it leverages the strengths of diverse data types and processing models to improve the accuracy and robustness of AI systems, particularly in complex environments where no single data type provides all the answers.
Deep Learning Architectures for Multimodal Learning
Deep learning has emerged as a powerful tool for building effective multimodal AI models. Here are some key architectures that play a crucial role:
- Convolutional Neural Networks (CNNs): These are excellent at feature extraction from image data. A CNN could scan medical images for possible malformations in a more complex multivariate diagnostic system.
- Recurrent Neural Networks (RNNs): These are good at coping with sequential data, such as text. In sentiment analysis, where both text and audio are integrated, an RNN may be useful to analyze the textual segment to grasp the sentiment conveyed by the words that were spoken.
- Transformer: This relatively new architecture has gained significant traction recently. Transformers are adept at learning long-range dependencies within data, making them suitable for various multimodal tasks. For instance, a transformer-based model could analyze both the visual content of an image and the accompanying text caption, establishing relationships between the two modalities for a more comprehensive understanding.
- Audio Model (MFCCs + Pitch): This model processes audio information (as well as features like pitch, for instance, potentially with the help of MFCCs or a pitch detection algorithm). It may then use these audio features to predict sentiment scores.
Applications of Multimodal AI
Multimodal AI's ability to process and integrate information from diverse sources is revolutionizing various fields. Here, we'll delve into some of the most promising applications of this technology:
Multimodal AI for Healthcare
The healthcare industry stands to gain significant benefits from multimodal AI. Here are a few examples:
- Medical Imaging Analysis: Multimodal AI can evaluate both a set of medical images, such as X-rays, CT scans, and MRI scans, and text documents, such as electronic medical records, to enhance disease diagnosis and treatment planning. Extending the scope of input data makes it easier to identify the signs of malfunctions at an earlier stage and more effectively.
- Drug Discovery: The drug discovery process is traditionally time-consuming and expensive. Multimodal AI can accelerate this process by analyzing vast amounts of data, including text analysis of scientific research papers, protein structure analysis (images), and clinical trial data. This allows researchers to identify promising drug candidates more effectively. In-silico Medicine is a leading name using the power of AI in AI-driven drug discovery. Horizon2020 research and Marie Skłodowska-Curie actions joined hands to initiate Advanced machine learning for Innovative Drug Discovery (AIDD)
- Personalized Medicine: Multimodal AI can facilitate personalized medicine by tailoring treatments to individual patients. By considering a patient's medical history (text), genetic data (genomics), and lifestyle factors (sensor data from wearables), AI systems can help doctors recommend the most effective treatment options.
Multimodal AI for Robotics and Self-Driving Cars
Robots and self-driving cars must perceive and understand their surroundings to navigate the real world effectively. Multimodal AI plays a crucial role in this through:
- Perception and Navigation: Self-driving cars perceive their environment using a combination of cameras (images), LiDAR (sensor data) that captures 3D information, and radar (sensor data). Multimodal AI fuses data from these sources, enabling the car to understand its surroundings and navigate safely and comprehensively.
- Human-Robot Interaction: Robots interacting with humans can benefit from multimodal AI by understanding spoken language and non-verbal cues like facial expressions (images) and gestures. This allows for more natural and intuitive interaction between humans and robots.
Human-Computer Interaction (HCI)
How we interact with computers is evolving with the help of multimodal AI. Here are some examples:
- Natural Language Processing (NLP): Conversational AI systems like virtual assistants get help from multimodal AI to understand not just the words we speak but also the tone of our voices (audio) and facial expressions (images) for a more natural understanding.
- Virtual Reality (VR) and Augmented Reality (AR): Multimodal AI can complement VR and AR by fusing real-world data (sensor data) and active user participation (voice commands, hand movements) to improve the overall user experience.
Challenges and Future Directions
Despite its immense potential, multimodal AI faces several challenges that need to be addressed for continued progress:
- Data Bias: Multimodal AI systems may be deemed untrustworthy because of biases in the data they are trained on. If the training data is biased toward certain demographics or situations, the AI model can extend those biases and lead to unfair outcomes. Reducing data bias involves choosing the right training data and the need for new approaches to deal with introduced bias within the model.
- Interpretability Limitations: It is often difficult to gain insight into how a multimodal AI model reaches certain conclusions, largely due to the interactions between different modalities within the model. This lack of interpretability may lead to a lack of trust in these systems, particularly for purposes, especially in applications such as healthcare. Researchers are actively exploring techniques to make multimodal AI models more easily interpretable.
- Computational Complexity: Training and running multimodal AI models often require significant computational resources due to the huge volume and variety of data. Developing more efficient algorithms and utilizing advanced hardware for AI, like GPUs, can help address these computational challenges.
Looking Ahead: The Future of Multimodal AI
The future of multimodal AI is bright, with ongoing research addressing the abovementioned challenges. Here are some exciting trends to watch:
- Multimodal Transformers: Transformer architectures are being adapted for multimodal learning tasks, and they show promise in achieving superior performance and interpretability compared to traditional approaches.
- Self-Supervised Learning for Multimodal Data: This emerging technique aims to train multimodal AI models without needing large amounts of labeled data. By leveraging the inherent relationships between different modalities, self-supervised learning can enable the development of more robust and efficient models.
- Explainable AI (XAI) for Multimodal Models: Explainable AI is a leap towards building trust in AI systems. Research in XAI techniques is crucial for building trust in multimodal AI systems. By developing methods to explain how these models make their decisions, we can ensure fairness, transparency, and responsible deployment of this technology.
In conclusion, multimodal AI represents a significant leap forward in artificial intelligence, mimicking the human brain's ability to process and integrate information from various sources. As we address the challenges and explore new directions, multimodal AI can revolutionize numerous fields, from healthcare and robotics to human-computer interaction.


