What are the Natural Language Processing Challenges, and How to Fix them?
Natural Language Processing is a subfield of Artificial Intelligence capable of breaking down human language and feeding the tenets of the same to the intelligent models. Have you planned to use NLP as your model training technology? Read on to know the challenges and solutions to fix them.

They say ‘Action speaks louder than Words’. Yet, in some cases, words (precisely deciphered) can determine the entire course of action relevant to highly intelligent machines and models. This approach to making the words more meaningful to the machines is NLP or Natural Language Processing.
For the unversed, NLP is a subfield of Artificial Intelligence capable of breaking down human language and feeding the tenets of the same to the intelligent models. NLP, paired with NLU (Natural Language Understanding) and NLG (Natural Language Generation), aims at developing highly intelligent and proactive search engines, grammar checkers, translates, voice assistants, and more.
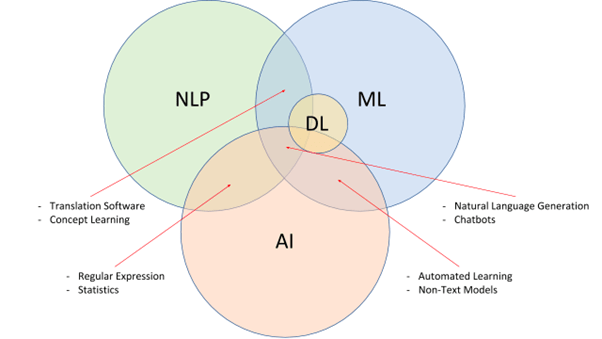
Simply put, NLP breaks down the language complexities, presents the same to machines as data sets to take reference from, and also extracts the intent and context to develop them further. Yet, implementing them comes with its share of challenges.

What is NLP: From a Startup’s Perspective?
It is hard for humans to learn a new language, let alone machines. However, if we need machines to help us out across the day, they need to understand and respond to the human-type of parlance. Natural Language Processing makes it easy by breaking down the human language into machine-understandable bits, used to train models to perfection.
Also, NLP has support from NLU, which aims at breaking down the words and sentences from a contextual point of view. Finally, there is NLG to help machines respond by generating their own version of human language for two-way communication.

Startups planning to design and develop chatbots, voice assistants, and other interactive tools need to rely on NLP services and solutions to develop the machines with accurate language and intent deciphering capabilities.
NLP Challenges to Consider
Words can have different meanings. Slangs can be harder to put out contextual. And certain languages are just hard to feed in, owing to the lack of resources. Despite being one of the more sought-after technologies, NLP comes with the following rooted and implementation AI challenges.
- Lack of Context for Homographs, Homophones, and Homonyms
A ‘Bat’ can be a sporting tool and even a tree-hanging, winged mammal. Despite the spelling being the same, they differ when meaning and context are concerned. Similarly, ‘There’ and ‘Their’ sound the same yet have different spellings and meanings to them.
Even humans at times find it hard to understand the subtle differences in usage. Therefore, despite NLP being considered one of the more reliable options to train machines in the language-specific domain, words with similar spellings, sounds, and pronunciations can throw the context off rather significantly.
- Ambiguity
If you think mere words can be confusing, here are is an ambiguous sentence with unclear interpretations.
“I snapped a kid in the mall with my camera”- If the spoken to, it can be the case that the machine gets confused as to whether the kid was snapped using the camera or when the kid was snapped, he had your camera.
This form of confusion or ambiguity is quite common if you rely on non-credible NLP solutions. As far as categorization is concerned, ambiguities can be segregated as Syntactic (meaning-based), Lexical (word-based), and Semantic (context-based).

- Errors relevant to Speed and Text
Machines relying on semantic feed cannot be trained if the speech and text bits are erroneous. This issue is analogous to the involvement of misused or even misspelled words, which can make the model act up over time. Even though evolved grammar correction tools are good enough to weed out sentence-specific mistakes, the training data needs to be error-free to facilitate accurate development in the first place.
- Inability to Fit in Slangs and Colloquialisms
Even if the NLP services try and scale beyond ambiguities, errors, and homonyms, fitting in slags or culture-specific verbatim isn’t easy. There are words that lack standard dictionary references but might still be relevant to a specific audience set. If you plan to design a custom AI-powered voice assistant or model, it is important to fit in relevant references to make the resource perceptive enough.
One example would be a ‘Big Bang Theory-specific ‘chatbot that understands ‘Buzzinga’ and even responds to the same.
- Apathy towards Vertical-Specific Lingo
Like the culture-specific parlance, certain businesses use highly technical and vertical-specific terminologies that might not agree with a standard NLP-powered model. Therefore, if you plan on developing field-specific modes with speech recognition capabilities, the process of entity extraction, training, and data procurement needs to be highly curated and specific.

- Lack of Usable Data
NLP hinges on the concepts of sentimental and linguistic analysis of the language, followed by data procurement, cleansing, labeling, and training. Yet, some languages do not have a lot of usable data or historical context for the NLP solutions to work around with.
- Lack of R&D
NLP implementation isn’t one-dimensional. Instead, it requires assistive technologies like neural networking and deep learning to evolve into something path-breaking. Adding customized algorithms to specific NLP implementations is a great way to design custom models—a hack that is often shot down due to the lack of adequate research and development tools.
Scale Above These Problems, Today: How to Choose the Right Vendor?
From fixing ambiguity to errors to issues with data collection, it is important to have the right vendor at your disposal to train and develop the envisioned NLP Model. And while several factors need to be considered, here are some of the more desirable features to consider while connecting:
- Sizable, domain-specific database (audio, speech, and video), regardless of the language.
- Capability to implement Part-of-Speech tagging for cutting out ambiguities.
- Support for custom assistive technologies like Mulingual Sentence Embeddings to improve the quality of interpretation.
- Seamless data annotation to label data sets as per the requirements.
- Multi-lingual database with off-the-shelf picks to work with.
Vendors offering most or even some of these features can be considered for designing your NLP models.

Wrap-Up
Needless to say, NLP has evolved into one of the more widely accepted and hailed Artificial Intelligence-powered technologies. If you are into specifics, the NLP market is expected to grow by almost 1400% by 2025, as compared to that in 2017. As per expectations and extrapolations, the NLP market will be valued at almost 43 billion by the end of 2025 - Statista
Despite the benefits, Natural Language Processing comes with a few limitations—something that you can address upon connecting with a reliable AI vendor.
Author
Vatsal Ghiya, founder of Shaip, is an entrepreneur with more than 20 years of experience in healthcare AI software and services.
