Boost Debt Collection and Recovery using Machine Learning [part 5/5]
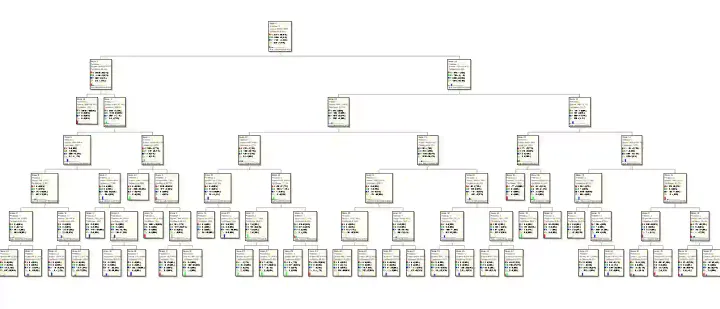
This is part-5 of the case study on Boost Debt Collections and Recoveries using Machine Learning (MLBR). A machine learning predictive model to enhance the current recovery system by creating focus groups for business to boost debt collection.
![Boost Debt Collection and Recovery using Machine Learning [part 5/5]](/content/images/size/w1200/2024/05/Debt_Recovery_Model.webp)