Predict Customer Attrition in Fintech using AI [part 1/5]
Machine Learning and Artificial Intelligence (AI) can be used to predict customer churn. Data Science case study performed in this article describes a machine learning predictive model trained on Fintech and digital data to predict customers attrition in advance.
![Predict Customer Attrition in Fintech using AI [part 1/5]](/content/images/size/w1200/2019/06/500_F_223365431_2DgPyt2u75tmkh0onQvsQHg0FhcyU94M.jpg)
Machine Learning and Artificial Intelligence AI can be used to predict customer churn or customer attrition. This article describes a data science case study that is based on machine learning model which is developed in Oracle R Enterprise using SQL Developer Advanced Analytics tool. The objective of the case study is to build and train a machine learning predictive model that should predict customers who are about to churn in next month or two. This case study is performed for a Fintech company.
This is the first article of the series on Predicting Customer Churn using Machine Learning and AI
Disclaimer: This case study is solely an educational exercise and information contained in this case study is to be used only as a case study example for teaching purposes. This hypothetical case study is provided for illustrative purposes only and do not represent an actual client or an actual client’s experience. All of the data, contents and information presented here have been altered and edited to protect the confidentiality and privacy of the company.
Background
Over the last few years, the number of customers with companies in Fintech sectors is increasing every day and this has made financial companies conscious of the quality of the services they offer. Churn or Attrition is the term used when customers shift loyalties from one service provider to another. This happens due to reasons such as availability of latest technology, customer-friendly staff, low interest rates, proximity of geographical location and mixed services offered. Hence, there is a pressing need to develop models that can predict which existing ‘loyal’ customer is going to churn in near future.
Research indicates that the online services customers have greater probability of churn than traditional customers.
Financial companies need to be proactive in understanding customer’s current satisfaction levels before they churn. Targeting customers on the basis of their changing purchase behavior could help the organizations do better business and loyalty reward programs helps the organizations build stronger relationships with customers.
Understanding the Business Case
In a world of ever growing competition on the market, companies have become aware that they should put much effort not only trying to convince customers to sign contracts, but also to retain existing clients.

Research have shown that in the current setting where people are given a huge choice of offers and different service providers to decide upon, winning new customers is a costly and hard process. Therefore, putting more effort in keeping churn rate low has become essential for financial companies.
Churn prediction problem is one of the most important concerns for financial companies and they would be interested to know their about-to-churn customers. Customer retention has great economic values which includes
- Lowering the need to seek new and potentially risky customers, this allows focusing on the demands of existing customers.
- Long-term customers tend to spend more.
- Positive word of mouth from satisfied customers is a good way for new customers’ acquisition.
- Long-term customers are less costly to serve, because of a larger database of their demands.
- Long-term customers are less sensitive to competitors’ marketing activities.
- Losing customer results in less spend and an increased need to attract new customers, which is five to six times more expensive than the money spent for retention of existing customers.
- People tend to share more often negative than positive service experience with friends, resulting in negative image of the company among possible future customers.
Business Objective
For Business, the objectives are to gain insights from its past data, and to identify customers at any stage of their life-cycle who are currently active but are likely to become inactive. This will help Business to create a churn management program to assess the potential impact and forestall the customer decay process.
Furthermore, the underlying objectives are to turn unprofitable customers to profitable ones. By implementing a predictive churn module, we want to reduce cost of acquisition by retaining existing customers as compared to acquiring potential new ones.
Problem Identification
Technically, customer churn is treated as a Classification problem which is one of the most common task in Data Science and Machine Learning. In classification, there is a target categorical variable which is partitioned into predetermined classes or categories. In this business case, we can think of an outcome variable "customer churn" with two possible classes (a) YES (b) NO.
For example, input a customer record, if model returns YES then customer will churn and vice versa in case of NO.
Proposed Approach
To predict customer churn we develop machine learning model that make predictions about unknown future events. Model uses many techniques from data mining, statistics, modeling, machine learning, and artificial intelligence to analyze current data and historical data to make predictions about future. Model develops profiles, discovers the factors that lead to certain outcomes, predicts the most likely outcomes, and identifies a degree of confidence in the predictions.
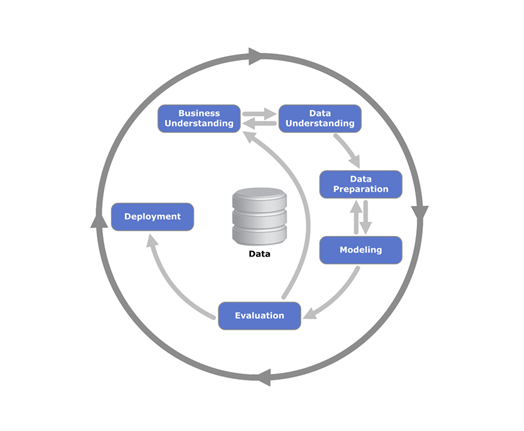
The most common methodology followed in doing machine learning projects is called as CRISP-DM (CRoss Industry Standard Process for Data Mining). It is a process model commonly employed for knowledge discovery that provides an overview of the life-cycle of a Data Mining project and suggests that efforts be partitioned into six phases as shown in Figure 1.
- Business Understanding
- Data Understanding
- Data Preparation/pre-processing
- Modeling
- Evaluation
- Real-world Validation and Deployment
In the next post of the series we will look into each of the six phases.
to be continued...