Predict Customer Attrition in Fintech using AI [part 2/5]
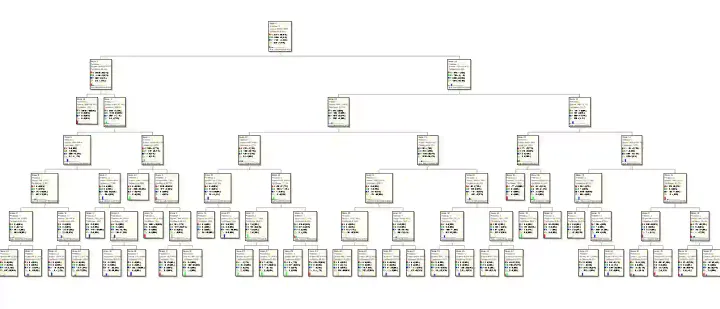
This is the second article of the series on Predicting Customer Churn using Machine Learning and AI. In the earlier post, we discussed our proposed approach which consists of six steps as given below
![Predict Customer Attrition in Fintech using AI [part 2/5]](/content/images/size/w1200/2019/11/586232cd77-reduce-customer-churn--1-.png)