Predict Customer Attrition in Fintech using AI [part 3/5]
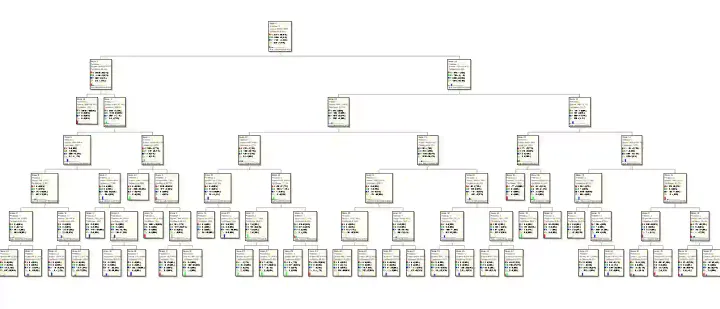
This is the third article of the series on Predicting Customer Churn using Machine Learning and AI. In this article, we will look Data Collection and Data Preparation.
![Predict Customer Attrition in Fintech using AI [part 3/5]](/content/images/size/w1200/2019/11/client-leaving.jpg)
This is the third article of the series on Predicting Customer Churn using Machine Learning and AI. In this article, we will look Data Collection and Data Preparation.